本教程由社区贡献,不获得 Open WebUI 团队的支持。它仅作为演示,说明如何根据您的特定用例定制 Open WebUI。想要贡献?请查看贡献教程。
🎨 图像生成
Open WebUI 支持通过三种后端进行图像生成:AUTOMATIC1111、ComfyUI 和 OpenAI DALL·E。本指南将帮助您设置和使用其中任何一个选项。
AUTOMATIC1111
Open WebUI 支持通过 AUTOMATIC1111 API 进行图像生成。以下是开始的步骤
初始设置
-
确保您已安装 AUTOMATIC1111。
-
启动 AUTOMATIC1111,并使用附加标志启用 API 访问
./webui.sh --api --listen -
对于预设了环境变量的 WebUI Docker 安装,请使用以下命令
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -e AUTOMATIC1111_BASE_URL=http://host.docker.internal:7860/ -e ENABLE_IMAGE_GENERATION=True -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
使用 AUTOMATIC1111 设置 Open WebUI
-
在 Open WebUI 中,导航到 管理面板 > 设置 > 图像 菜单。
-
将
Image Generation Engine字段设置为Default (Automatic1111)。 -
在 API URL 字段中,输入 AUTOMATIC1111 API 可访问的地址
http://<your_automatic1111_address>:7860/如果您在同一主机上运行 Open WebUI 和 AUTOMATIC1111 的 Docker 安装,请使用
http://host.docker.internal:7860/作为您的地址。
ComfyUI
ComfyUI 提供了一个用于管理和交互图像生成模型的替代界面。您可以从其 GitHub 页面了解更多或下载。以下是使 ComfyUI 与其他工具一起运行的设置说明。
初始设置
-
从 GitHub 下载 ComfyUI 软件包并将其解压到您想要的目录。
-
要启动 ComfyUI,运行以下命令
python main.py对于 VRAM 较低的系统,请使用附加标志启动 ComfyUI 以减少内存使用。
python main.py --lowvram -
对于预设了环境变量的 WebUI Docker 安装,请使用以下命令
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -e COMFYUI_BASE_URL=http://host.docker.internal:7860/ -e ENABLE_IMAGE_GENERATION=True -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
使用 ComfyUI 设置 Open WebUI
设置 FLUX.1 模型
- 模型检查点:
- 从 black-forest-labs HuggingFace 页面下载
FLUX.1-schnell或FLUX.1-dev模型。 - 将模型检查点放置在 ComfyUI 的
models/checkpoints和models/unet两个目录中。或者,您可以在models/checkpoints和models/unet之间创建符号链接,以确保两个目录包含相同的模型检查点。
- VAE 模型:
- 从此处下载
ae.safetensorsVAE。 - 将其放置在 ComfyUI 的
models/vae目录中。
- CLIP 模型:
- 从此处下载
clip_l.safetensors。 - 将其放置在 ComfyUI 的
models/clip目录中。
- T5XXL 模型:
- 从此处下载
t5xxl_fp16.safetensors或t5xxl_fp8_e4m3fn.safetensors模型。 - 将其放置在 ComfyUI 的
models/clip目录中。
要将 ComfyUI 集成到 Open WebUI 中,请按照以下步骤操作
步骤 1:配置 Open WebUI 设置
- 在 Open WebUI 中导航到管理面板。
- 点击设置,然后选择图像选项卡。
- 在
Image Generation Engine字段中,选择ComfyUI。 - 在 API URL 字段中,输入 ComfyUI API 可访问的地址,格式如下:
http://<your_comfyui_address>:8188/。- 将环境变量
COMFYUI_BASE_URL设置为此地址,以确保它在 WebUI 中持久化。
- 将环境变量
步骤 2:验证连接并启用图像生成
- 确保 ComfyUI 正在运行,并且您已成功验证与 Open WebUI 的连接。如果没有成功连接,您将无法继续。
- 连接验证成功后,开启图像生成(实验性)。将显示更多选项。
- 继续步骤 3 进行最终配置。
步骤 3:配置 ComfyUI 设置并导入工作流
- 在 ComfyUI 中启用开发者模式。为此,请在 ComfyUI 中寻找 Queue Prompt 按钮上方的齿轮图标,并启用
Dev Mode开关。 - 使用
Save (API Format)按钮以API format从 ComfyUI 导出所需的工作流。如果操作正确,文件将下载为workflow_api.json。 - 返回 Open WebUI,点击点击此处上传 workflow.json 文件按钮。
- 选择
workflow_api.json文件,将从 ComfyUI 导出的工作流导入到 Open WebUI 中。 - 导入工作流后,您必须根据导入的工作流节点 ID 映射
ComfyUI Workflow Nodes。 - 将
Set Default Model设置为正在使用的模型文件名,例如flux1-dev.safetensors
您可能需要在 Open WebUI 的 ComfyUI Workflow Nodes 部分中调整一个或两个 Input Key,以匹配您工作流中的节点。例如,seed 可能需要重命名为 noise_seed,以匹配您导入工作流中的节点 ID。
某些工作流(例如使用任何 Flux 模型的工作流)可能需要利用多个节点 ID 来填充其在 Open WebUI 中的节点输入字段。如果节点输入字段需要多个 ID,则节点 ID 应该用逗号分隔(例如 1 或 1, 2)。
- 点击
Save保存设置,享受 ComfyUI 集成到 Open WebUI 中的图像生成吧!
完成这些步骤后,您的 ComfyUI 设置应已与 Open WebUI 集成,并且您可以使用 Flux.1 模型进行图像生成。
使用 SwarmUI 配置
SwarmUI 使用 ComfyUI 作为其后端。为了使 Open WebUI 与 SwarmUI 协同工作,您需要将 ComfyBackendDirect 附加到 ComfyUI Base URL。此外,您还需要将 SwarmUI 设置为 LAN 访问。经过上述调整后,将 SwarmUI 设置为与 Open WebUI 协同工作的方式与上述步骤一:配置 Open WebUI 设置相同。
SwarmUI API URL
您将输入作为 ComfyUI Base URL 的地址将类似于:http://<your_swarmui_address>:7801/ComfyBackendDirect。
OpenAI
Open WebUI 还支持通过 OpenAI API 进行图像生成。此选项包括一个选择器,用于在 DALL·E 2、DALL·E 3 和 GPT-Image-1 之间进行选择,每个都支持不同的图像尺寸。
初始设置
- 从 OpenAI 获取 API 密钥。
配置 Open WebUI
- 在 Open WebUI 中,导航到 管理面板 > 设置 > 图像 菜单。
- 将
Image Generation Engine字段设置为Open AI。 - 输入您的 OpenAI API 密钥。
- 选择您希望使用的模型。请注意,图像尺寸选项将取决于所选模型
- DALL·E 2:支持
256x256、512x512或1024x1024图像。 - DALL·E 3:支持
1024x1024、1792x1024或1024x1792图像。 - GPT-Image-1:支持
auto、1024x1024、1536x1024或1024x1536图像。
- DALL·E 2:支持
Azure OpenAI
直接使用 Azure OpenAI Dall-E 不受支持,但您可以设置 LiteLLM 代理,该代理与 Open AI (Dall-E) 图像生成引擎兼容。
Image Router
Image Router 是一个开源图像生成代理,它将大多数流行模型统一到一个 API 中。
初始设置
- 从 Image Router 获取 API 密钥。
配置 Open WebUI
- 在 Open WebUI 中,导航到 管理面板 > 设置 > 图像 菜单。
- 将
Image Generation Engine字段设置为Open AI(Image Router 使用与 OpenAI 相同的语法)。 - 将 API 端点 URL 更改为
https://api.imagerouter.io/v1/openai - 输入您的 Image Router API 密钥。
- 输入您希望使用的模型。请勿使用下拉菜单选择模型,而是直接输入模型名称。欲了解更多信息,请查看所有模型。
使用图像生成
方法 1:
- 将
Image Generation开关切换为开启。 - 输入您的图像生成提示。
- 点击
Send。
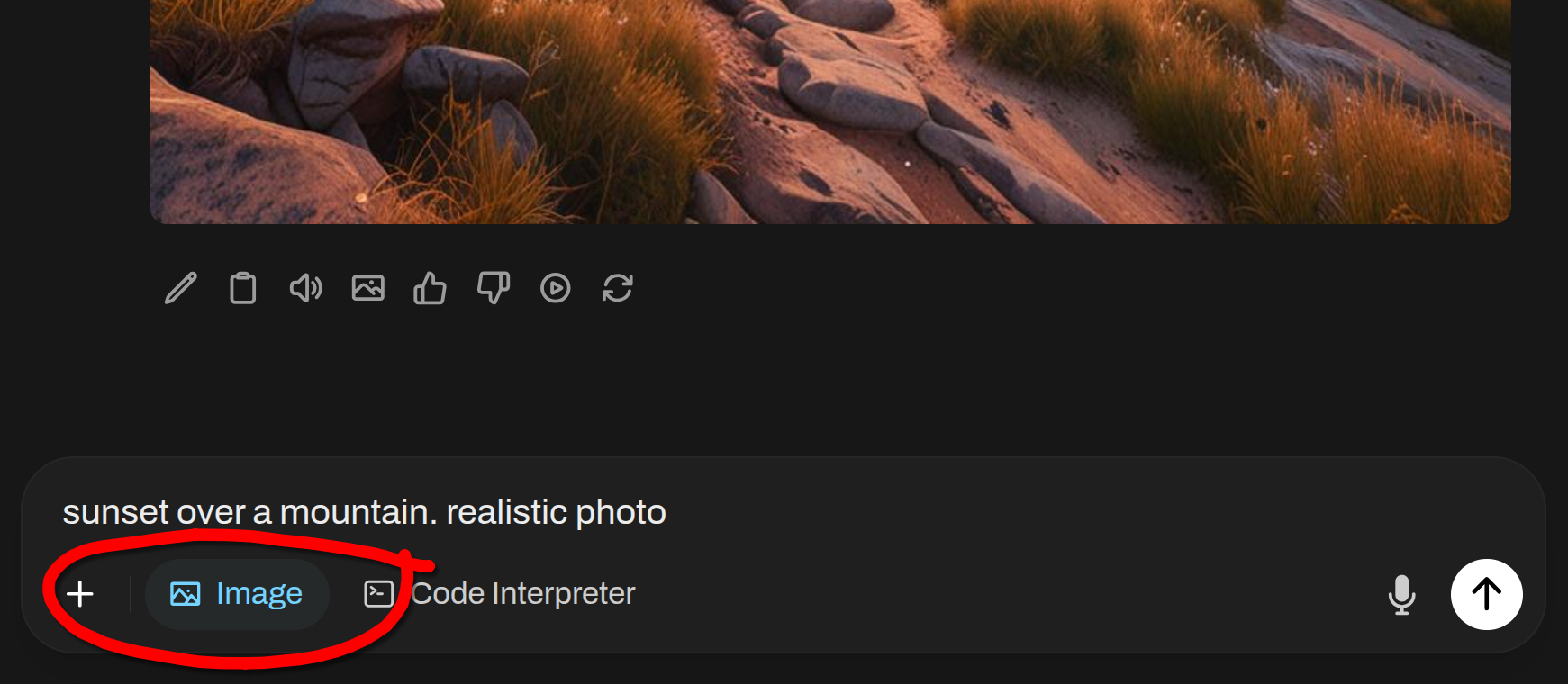
方法 2:
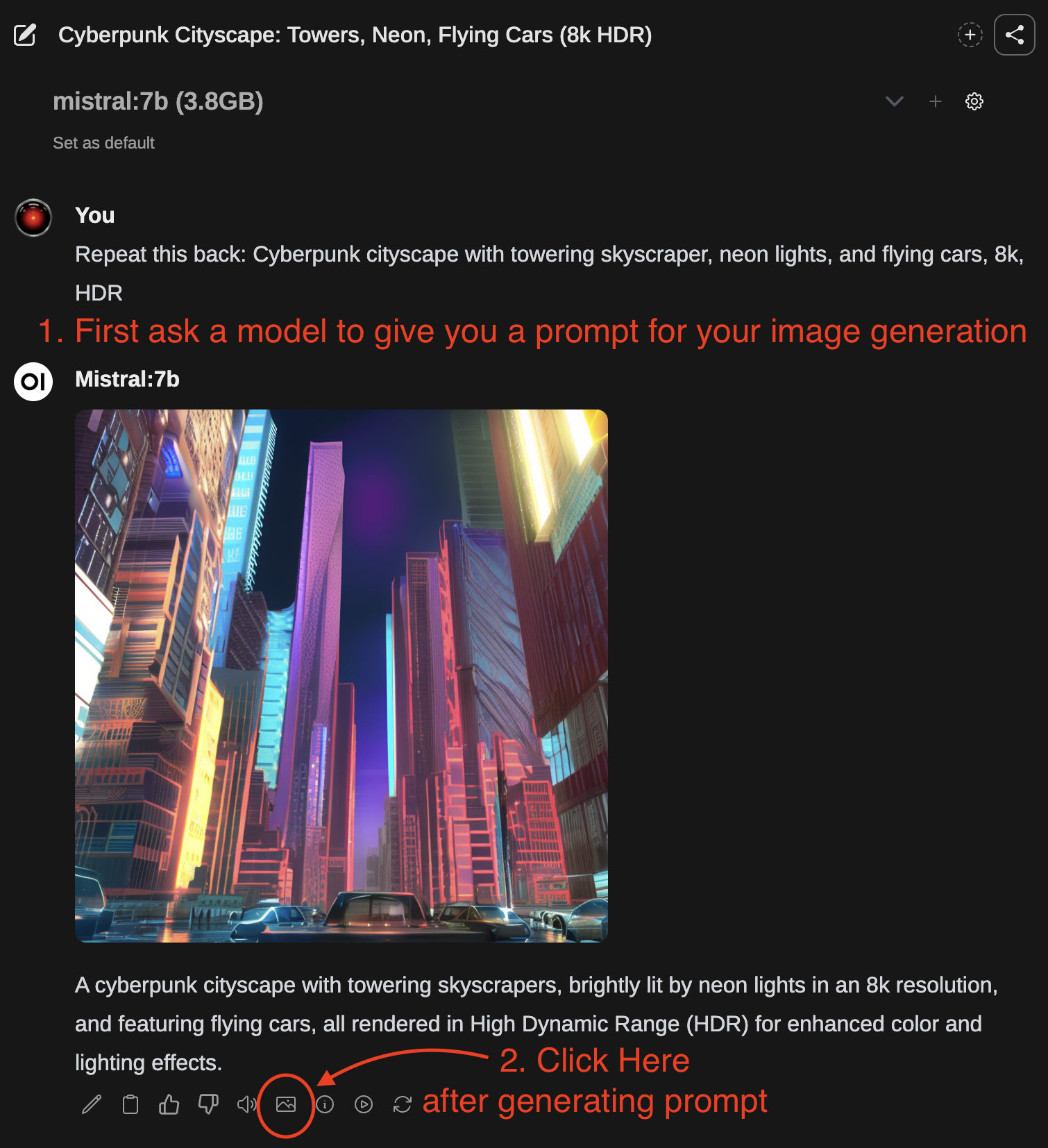
- 首先,使用文本生成模型来编写图像生成提示。
- 响应完成后,您可以点击图片图标来生成图像。
- 图像生成完成后,它将自动在聊天中返回。
您还可以编辑 LLM 的响应,并将您的图像生成提示作为消息发送,而不是使用 LLM 提供的实际响应。